Applying AI for Enhanced Patient Data Matching
Challenges
Let’s face the fact humans hate routine, mundane tasks. That’s why we try to teach computers to perform as many tedious processes as possible instead of us. Data matching solution which is a perfect example of such activities. Even though there are a lot of challenges for computers to execute this task, they still do it better than us, since human beings can get tired and become less attentive to details. Data matching or Record Linking is the process of identifying which records from data sources correspond to the same real-world entity.
The purpose can be to find entries that are related to the same subject or to detect duplicates in the database. Although the task might seem simple for a human, there are quite many issues computers face.
First of all, data matching techniques rely on the quality of information a lot. Let’s take a database with names, addresses, and birthdays of people. If some dates are entered in the US format, and others – in the international format, a computer will struggle to compare the attributes. Thus, to make sure that algorithms do everything correctly, we first need to process the information and ensure a basic quality level. Otherwise, the system won’t be able to complete the task and offer accurate results.
Another complexity is that data matching algorithms usually have to work with vast databases. The more records there are to compare to each other, the more time this process takes. Also, these difficult tasks will be quite expensive to execute. Sometimes this problem can be fixed with indexes that can remove the data that has no match. But it’s not always possible to do so.

"The third and the most important problem is that there is no standard unique identifier for the patient database matching which demands new heuristics to find the potential matches".
Transformative Change with Probabilistic Matching Technique
Moreover, Since the novel corona virus was first detected in December 2019 approximately 1.3 million cases have been reported worldwide. With such enormous increase in the number of infected people, the hospitals are experiencing a huge influx of patients. This demands a transformative change in the public health care industry. This causes huge amount of miscommunication and patient data mismatching. In 2019, it was reported that approximately 18 percent of patient EHR's are duplicates or incomplete. So matching patient data is of significant importance because errors in data matching possess a considerable threat to the delivery of suitable care and patient safety, and can lead to potentially fatal consequences.
Owing to the immense importance of patient data matching, significant advances have been achieved in many aspects of the matching process, but the data matching tools are limited to heuristic method where all the attributes of the patient are checked for potential matches based on the logical rules devised. But this approach is tedious, time consuming and will fail if there are missing data or if the data formats are different. So advances in probabilistic matching techniques and tools like record linkage helped solve the problem with respect to changing data formats and missing data but they compare individual attributes where the algorithm is not aware of amount of importance that has to be given to individual features to estimate holistically about the potential matches.
Solution with Machine Learning
To overcome both these problems, Machine learning methods were incorporated but they demand labeled data which is not possible to obtain or might create a bias due to the training set distribution.
So to overcome all these issues and to address the need of the hour we offer a solution using a combination of probabilistic matching and machine learning. We device a custom loss functions for all the attributes and optimize them using a weighted average combination of the all the loss functions according the rank of feature importance. This is done by a custom derived equation which ensures that the required features are optimized according to their importance. This feature importance rank is obtained from the industrial standards.
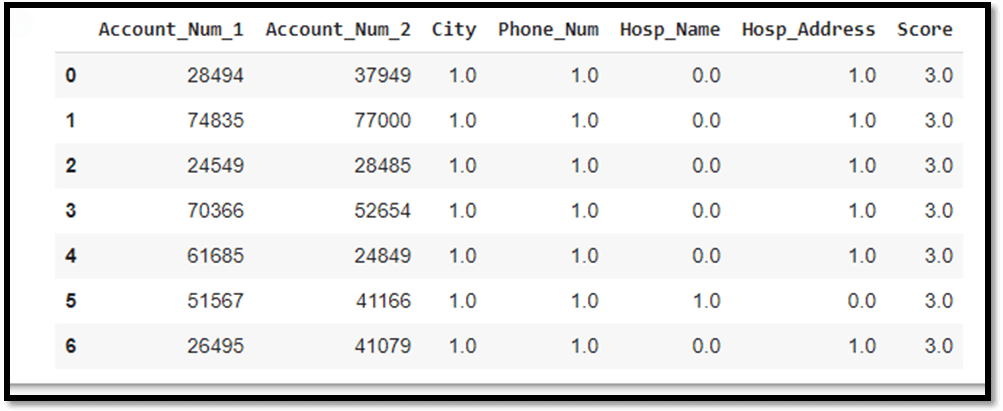
Finally the global minima of loss function will help us find the potential match in an unsupervised manner. This technically eliminates all the existing problems and provides a robust solution. We used two standard approaches to do the column wise matching. They are fuzzy matcher and record linkage. These tools can be imported from standard python libraries. We used functions like string compare, String group by, String match and more. Here we defined Custom user defined functions to carry out potential matching. We will be further moving on to implement this algorithm as a data matching software which can be deployed in the entire health care sector.
Bottom line
We live in a world of big data. All the industries from complex ones like pharmaceuticals and biotech to less sophisticated sectors like e-commerce have a lot of information to work with. It is incredibly inefficient to try processing all this data manually. The process will take a lot of time, human labor and, of course, costs.
That’s why businesses all over the globe start implementing data matching service in their workflows. Computers can process information better and faster than humans — especially, given that the machine learning industry evolves continuously and quickly. The technology gets more advanced every day offering companies better solutions.
Considering that the volume of data will continue increasing significantly, businesses that still don’t use data matching technology should consider trying it. Algorithms will help to structure all the information, as well as provide the business owner with loads of valuable insights. So in the end, the entrepreneur gets another advantage from using data matching – the opportunity to spot tendencies and make data-driven decisions. Thus, there’s little to no chance of making a mistake and leading the company in the wrong direction.
"The entrepreneur gets another advantage from using data matching – the opportunity to spot tendencies and make data-driven decisions".
